


















Python必看:为什么Python 多线程的效率不升反降?
在Python学习或项目开发过程中,许多小伙伴反应说Python 多线程是鸡肋,效率不升反降。难道多线程不好吗?在我们的常识中,多线程通过并发模式充分利用硬件资源,大大提升了程序的运行效率,怎么在 Python 中反而成了鸡肋呢?
Python中的多线程是不是鸡肋,我们先做个实验,实验非常简单,就是将数字 “1亿” 递减,减到 0 程序就终止,这个任务如果我们使用单线程来执行,完成时间会是多少?使用多线程又会是多少?
单线程
在我的4核 CPU 计算机中,单线程所花的时间是 6.5 秒。
多线程
创建两个子线程 t1、t2,每个线程各执行 5 千万次减操作,等两个线程都执行完后,主线程终止程序运行。结果,两个线程以合作的方式执行是 6.8 秒,反而变慢了。按理来说,两个线程同时并行地运行在两个 CPU 之上,时间应该减半才对,现在不减反增。
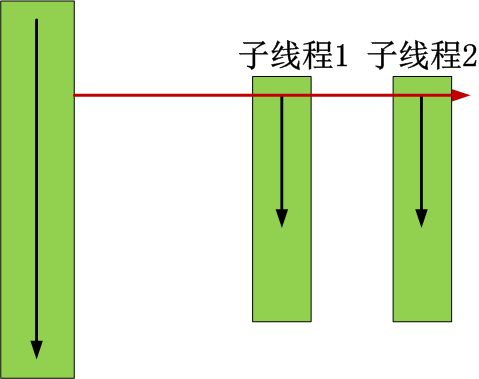
是什因导致多线么原程不快反慢的呢?
原因就在于 GIL ,在 Cpython 解释器中,有一把全局解释锁(Global Interpreter Lock),在解释器解释执行 Python 代码时,先要得到这把锁,意味着,任何时候只可能有一个线程在执行代码,其它线程要想获得 CPU 执行代码指令,就必须先获得这把锁,如果锁被其它线程占用了,那么该线程就只能等待,直到占有该锁的线程释放锁才有执行代码指令的可能。
因此,这也就是为什么两个线程一起执行反而更加慢的原因,因为同一时刻,只有一个线程在运行,其它线程只能等待,即使是多核CPU,也没办法让多个线程并行执行代码,只能是交替执行,因为多线程涉及到上线文切换、锁机制处理(获取锁,释放锁等),所以,多线程执行不快反慢。
什么时候 GIL 被释放呢?
当一个线程遇到 I/O 任务时,将释放GIL。计算密集型(CPU-bound)线程执行 100 次解释器的计步(ticks)时(计步可粗略看作 Python 虚拟机的指令),也会释放 GIL。可以通过设置计步长度,查看计步长度。相比单线程,这些多是多线程带来的额外开销
CPython 解释器为什么要这样设计?
多线程是为了适应现代计算机硬件高速发展充分利用多核处理器的产物,通过多线程使得 CPU 资源可以被高效利用起来。
但是多线程有个问题,怎么解决共享数据的同步、一致性问题,因为,对于多个线程访问共享数据时,可能有两个线程同时修改一个数据情况,如果没有合适的机制保证数据的一致性,那么程序最终导致异常,所以,Python之父就搞了个全局的线程锁,不管你数据有没有同步问题,反正一刀切,上个全局锁,保证数据安全。
这种解决办法放在90年代,其实是没什么问题的,毕竟,那时候的硬件配置还很简陋,单核 CPU 还是主流,多线程的应用场景也不多。
- 赞
